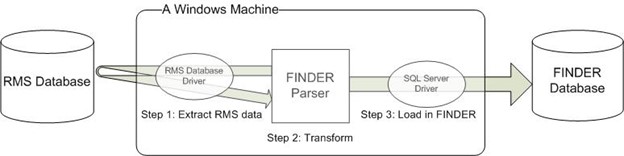
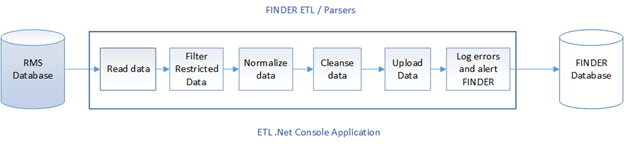
Data normalization is the process of injecting structure and order into the data. FINDER parsers extract data entities (persons, vehicles, cases, etc.) from structured data sources like databases and from unstructured data sources like text files. In either case, the data is transformed to the FINDER structure and loaded into FINDER.
Besides injecting structure in data entities, data elements like race, sex, location, etc., are structured using the following methods:
- Code mapping: Codes like hair color, eye color, race, sex, etc. are mapped to a standard code like FCIC or NCIC.
- Standardization: Data fields can be standardized for consistency. For example, “WEST” can be abbreviated to “W”; full names can be formatted as last name, first name, middle initial, etc.
- Geocoding.